
'%3e%3cpath d='M10.8319730758667%2c16.66630220413208L10.8319730758667%2c20.832922204132082L11.665297075866699%2c20.832922204132082C13.9664530758667%2c20.832922204132082%2c15.831913075866698%2c18.96746220413208%2c15.831913075866698%2c16.66630220413208L10.8319730758667%2c16.66630220413208Z' fill='black' fill-opacity='1'/%3e%3c/g%3e%3c/g%3e%3cg%3e%3cpath d='M27.499679565429688%2c16.428394391632082L30.322619565429687%2c16.428394391632082L30.322619565429687%2c11.96290439163208L32.134769565429686%2c11.96290439163208L34.68451956542969%2c16.428394391632082L37.84437956542969%2c16.428394391632082L34.95770956542969%2c11.47891439163208Q36.05955956542969%2c10.94013439163208%2c36.696999565429685%2c9.94019439163208Q37.33443956542969%2c8.940254391632081%2c37.33443956542969%2c7.67092439163208Q37.33443956542969%2c5.78976439163208%2c36.03679956542969%2c4.56153439163208Q34.739149565429685%2c3.33329439163208%2c32.77219956542969%2c3.33329439163208L27.499679565429688%2c3.33329439163208L27.499679565429688%2c16.428394391632082ZM72.31817956542969%2c5.9280443916320795L70.02697956542968%2c5.9280443916320795L70.02697956542968%2c3.33329439163208L72.31817956542969%2c3.33329439163208L72.31817956542969%2c5.9280443916320795ZM98.07867956542968%2c16.428394391632082L95.31417956542968%2c16.428394391632082L95.31417956542968%2c3.33329439163208L98.07867956542968%2c3.33329439163208L98.07867956542968%2c8.38321439163208L102.89427956542968%2c8.38321439163208L102.89427956542968%2c3.33329439163208L105.65887956542969%2c3.33329439163208L105.65887956542969%2c16.428394391632082L102.89427956542968%2c16.428394391632082L102.89427956542968%2c11.01318439163208L98.07867956542968%2c11.01318439163208L98.07867956542968%2c16.428394391632082ZM108.27917956542969%2c14.99369439163208Q106.80827956542969%2c13.55909439163208%2c106.80827956542969%2c11.32442439163208L106.80827956542969%2c3.33329439163208L109.52317956542969%2c3.33329439163208L109.52317956542969%2c11.19928439163208Q109.52317956542969%2c12.388124391632081%2c110.20847956542968%2c13.103214391632081Q110.89377956542968%2c13.81829439163208%2c111.98497956542968%2c13.81829439163208Q113.07617956542968%2c13.81829439163208%2c113.75707956542969%2c13.103214391632081Q114.43807956542969%2c12.388124391632081%2c114.43807956542969%2c11.19928439163208L114.43807956542969%2c3.33329439163208L117.15297956542969%2c3.33329439163208L117.15297956542969%2c11.32442439163208Q117.15297956542969%2c13.55909439163208%2c115.68637956542969%2c14.99369439163208Q114.21977956542969%2c16.428394391632082%2c111.98497956542968%2c16.428394391632082Q109.75017956542969%2c16.428394391632082%2c108.27917956542969%2c14.99369439163208ZM118.30237956542969%2c16.428394391632082L123.58037956542968%2c16.428394391632082Q125.2010795654297%2c16.428394391632082%2c126.34937956542969%2c15.32339439163208Q127.49767956542969%2c14.21849439163208%2c127.49767956542969%2c12.64779439163208Q127.49767956542969%2c11.60675439163208%2c127.04707956542968%2c10.78945439163208Q126.59637956542969%2c9.972154391632081%2c125.77307956542968%2c9.52469439163208Q126.43167956542969%2c9.04070439163208%2c126.80437956542968%2c8.29189439163208Q127.1770795654297%2c7.54308439163208%2c127.1770795654297%2c6.70295439163208Q127.1770795654297%2c5.26011439163208%2c126.11107956542969%2c4.29670539163208Q125.04507956542969%2c3.33329439163208%2c123.44167956542968%2c3.33329439163208L118.30237956542969%2c3.33329439163208L118.30237956542969%2c16.428394391632082ZM50.60827956542968%2c7.00483439163208Q49.339479565429684%2c8.29581439163208%2c49.339479565429684%2c10.40660439163208L49.339479565429684%2c16.42799439163208L51.98317956542969%2c16.42799439163208L51.98317956542969%2c10.72699439163208Q51.98317956542969%2c9.61505439163208%2c52.504779565429686%2c8.98841439163208Q53.02647956542969%2c8.36177439163208%2c53.94597956542969%2c8.36177439163208Q54.865579565429684%2c8.36177439163208%2c55.37837956542968%2c8.99312439163208Q55.89117956542969%2c9.62448439163208%2c55.89117956542969%2c10.72699439163208L55.89117956542969%2c16.42799439163208L58.53477956542969%2c16.42799439163208L58.53477956542969%2c10.40660439163208Q58.53477956542969%2c8.29581439163208%2c57.27927956542969%2c7.00483439163208Q56.02377956542969%2c5.713864391632081%2c53.94597956542969%2c5.713864391632081Q51.87707956542969%2c5.713864391632081%2c50.60827956542968%2c7.00483439163208ZM60.952079565429685%2c7.00483439163208Q59.683279565429686%2c8.29581439163208%2c59.683279565429686%2c10.40660439163208L59.683279565429686%2c16.42799439163208L62.326879565429685%2c16.42799439163208L62.326879565429685%2c10.72699439163208Q62.326879565429685%2c9.61505439163208%2c62.84857956542969%2c8.98841439163208Q63.37027956542969%2c8.36177439163208%2c64.28977956542968%2c8.36177439163208Q65.20927956542968%2c8.36177439163208%2c65.72207956542968%2c8.99312439163208Q66.23487956542968%2c9.62448439163208%2c66.23487956542968%2c10.72699439163208L66.23487956542968%2c16.42799439163208L68.87857956542969%2c16.42799439163208L68.87857956542969%2c10.40660439163208Q68.87857956542969%2c8.29581439163208%2c67.62307956542969%2c7.00483439163208Q66.36757956542968%2c5.713864391632081%2c64.28977956542968%2c5.713864391632081Q62.22077956542969%2c5.713864391632081%2c60.952079565429685%2c7.00483439163208ZM74.74497956542969%2c7.00483439163208Q73.47627956542968%2c8.29581439163208%2c73.47627956542968%2c10.40660439163208L73.47627956542968%2c16.42799439163208L76.11987956542968%2c16.42799439163208L76.11987956542968%2c10.72699439163208Q76.11987956542968%2c9.61505439163208%2c76.64157956542968%2c8.98841439163208Q77.16317956542969%2c8.36177439163208%2c78.08277956542969%2c8.36177439163208Q79.00227956542969%2c8.36177439163208%2c79.51507956542969%2c8.99312439163208Q80.02787956542969%2c9.62448439163208%2c80.02787956542969%2c10.72699439163208L80.02787956542969%2c16.42799439163208L82.67157956542968%2c16.42799439163208L82.67157956542968%2c10.40660439163208Q82.67157956542968%2c8.29581439163208%2c81.4159795654297%2c7.00483439163208Q80.16047956542968%2c5.713864391632081%2c78.08277956542969%2c5.713864391632081Q76.01377956542969%2c5.713864391632081%2c74.74497956542969%2c7.00483439163208ZM40.26257956542969%2c15.13739439163208Q38.99377956542969%2c13.84639439163208%2c38.99377956542969%2c11.73563439163208L38.99377956542969%2c5.71421439163208L41.637479565429686%2c5.71421439163208L41.637479565429686%2c11.415244391632081Q41.637479565429686%2c12.52717439163208%2c42.159079565429685%2c13.15381439163208Q42.68077956542969%2c13.78049439163208%2c43.60027956542969%2c13.78049439163208Q44.51987956542969%2c13.78049439163208%2c45.03267956542969%2c13.149104391632081Q45.54547956542969%2c12.51775439163208%2c45.54547956542969%2c11.415244391632081L45.54547956542969%2c5.71421439163208L48.18907956542969%2c5.71421439163208L48.18907956542969%2c11.73563439163208Q48.18907956542969%2c13.84639439163208%2c46.93357956542969%2c15.13739439163208Q45.678079565429684%2c16.428394391632082%2c43.60027956542969%2c16.428394391632082Q41.53137956542969%2c16.428394391632082%2c40.26257956542969%2c15.13739439163208ZM83.81997956542969%2c10.77387439163208Q83.81997956542969%2c12.16869439163208%2c84.46707956542969%2c13.33104439163208Q85.11417956542968%2c14.49339439163208%2c86.24327956542969%2c15.15889439163208Q87.3723795654297%2c15.82439439163208%2c88.72907956542969%2c15.82439439163208Q90.2909795654297%2c15.82439439163208%2c91.54947956542969%2c14.92189439163208L91.54947956542969%2c15.30479439163208Q91.54947956542969%2c16.38049439163208%2c90.8354795654297%2c17.02319439163208Q90.12137956542969%2c17.66589439163208%2c89.07717956542969%2c17.66589439163208Q88.29167956542969%2c17.66589439163208%2c87.62677956542969%2c17.30579439163208Q86.96177956542968%2c16.94569439163208%2c86.74757956542969%2c16.29849439163208L84.0966795654297%2c16.29849439163208Q84.43587956542969%2c18.03059439163208%2c85.7746795654297%2c19.01519439163208Q87.11347956542969%2c19.99979439163208%2c89.12177956542969%2c19.99979439163208Q91.46917956542968%2c19.99979439163208%2c92.81697956542969%2c18.63689439163208Q94.1646795654297%2c17.27389439163208%2c94.1646795654297%2c14.91279439163208L94.1646795654297%2c6.90467439163208L92.31847956542968%2c6.90467439163208C92.11627956542969%2c6.90467439163208%2c91.92137956542969%2c6.827694391632081%2c91.76127956542969%2c6.704104391632081Q90.47887956542968%2c5.71421439163208%2c88.72907956542969%2c5.71421439163208Q87.3723795654297%2c5.71421439163208%2c86.24327956542969%2c6.388834391632081Q85.11417956542968%2c7.06345439163208%2c84.46707956542969%2c8.22580439163208Q83.81997956542969%2c9.388164391632081%2c83.81997956542969%2c10.77387439163208ZM120.94497956542969%2c8.538464391632079L123.18097956542968%2c8.538464391632079Q123.81367956542968%2c8.538464391632079%2c124.19067956542969%2c8.150364391632081Q124.56767956542969%2c7.76225439163208%2c124.56767956542969%2c7.14129439163208Q124.56767956542969%2c6.52032439163208%2c124.18627956542969%2c6.13678439163208Q123.80497956542969%2c5.75324439163208%2c123.18097956542968%2c5.75324439163208L120.94497956542969%2c5.75324439163208L120.94497956542969%2c8.538464391632079ZM30.321949565429687%2c5.95414439163208L30.321949565429687%2c9.34206439163208L32.580299565429684%2c9.34206439163208Q33.454499565429686%2c9.34206439163208%2c33.96444956542969%2c8.87177439163208Q34.474399565429685%2c8.401484391632081%2c34.474399565429685%2c7.65267439163208Q34.474399565429685%2c6.9038543916320805%2c33.96444956542969%2c6.4290043916320805Q33.454499565429686%2c5.95414439163208%2c32.580299565429684%2c5.95414439163208L30.321949565429687%2c5.95414439163208ZM72.32587956542969%2c16.428394391632082L70.02697956542968%2c16.428394391632082L70.02697956542968%2c7.30008439163208L72.32587956542969%2c7.30008439163208L72.32587956542969%2c16.428394391632082ZM86.54067956542968%2c10.77388439163208Q86.54067956542968%2c11.90432439163208%2c87.25457956542968%2c12.64732439163208Q87.96847956542969%2c13.39029439163208%2c89.07297956542969%2c13.39029439163208Q90.16847956542969%2c13.39029439163208%2c90.8868795654297%2c12.64732439163208Q91.60527956542968%2c11.90432439163208%2c91.60527956542968%2c10.77388439163208Q91.60527956542968%2c9.65255439163208%2c90.89137956542969%2c8.91867439163208Q90.17747956542968%2c8.18479439163208%2c89.07297956542969%2c8.18479439163208Q87.97747956542969%2c8.18479439163208%2c87.25907956542969%2c8.91867439163208Q86.54067956542968%2c9.65255439163208%2c86.54067956542968%2c10.77388439163208ZM120.94497956542969%2c13.82579439163208L123.32827956542968%2c13.82579439163208Q123.98697956542969%2c13.82579439163208%2c124.38997956542968%2c13.41489439163208Q124.79297956542969%2c13.00394439163208%2c124.79297956542969%2c12.35558439163208Q124.79297956542969%2c11.71635439163208%2c124.38997956542968%2c11.30541439163208Q123.98697956542969%2c10.89448439163208%2c123.32827956542968%2c10.89448439163208L120.94497956542969%2c10.89448439163208L120.94497956542969%2c13.82579439163208Z' fill-rule='evenodd' fill='white' fill-opacity='1'/%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
'%3e%3cg%3e%3cpath d='M3.387858046875%2c3.3877359765625Q1.166748046875%2c5.6088559765625%2c1.166748046875%2c8.7499559765625Q1.166748046875%2c11.8910259765625%2c3.387858046875%2c14.1122259765625Q5.608978046875%2c16.3333259765625%2c8.750078046875%2c16.3333259765625Q11.891148046875%2c16.3333259765625%2c14.112348046875%2c14.1122259765625Q16.333448046875%2c11.8910259765625%2c16.333448046875%2c8.7499559765625Q16.333448046875%2c5.6088559765625%2c14.112348046875%2c3.3877359765625Q11.891148046875%2c1.1666259765625%2c8.750078046875%2c1.1666259765625Q5.608978046875%2c1.1666259765625%2c3.387858046875%2c3.3877359765625ZM4.094968046875%2c13.4050259765625Q2.166748046875%2c11.4768559765625%2c2.166748046875%2c8.7499559765625Q2.166748046875%2c6.0230659765625%2c4.094968046875%2c4.0948459765625Q6.023188046875%2c2.1666259765625%2c8.750078046875%2c2.1666259765625Q11.476968046875%2c2.1666259765625%2c13.405148046875%2c4.0948459765625Q15.333448046875%2c6.0230659765625%2c15.333448046875%2c8.7499559765625Q15.333448046875%2c11.4768459765625%2c13.405148046875%2c13.4050259765625Q11.476978046875%2c15.3333259765625%2c8.750078046875%2c15.3333259765625Q6.023188046875%2c15.3333259765625%2c4.094968046875%2c13.4050259765625Z' fill-rule='evenodd' fill='white' fill-opacity='1'/%3e%3c/g%3e%3cg%3e%3cpath d='M14.196142296875%2c13.4889132265625L17.731629296875%2c17.0243972265625Q17.801949296875%2c17.0947172265625%2c17.840009296875%2c17.1866072265625Q17.878069296875%2c17.2784972265625%2c17.878069296875%2c17.3779472265625Q17.878069296875%2c17.427197226562498%2c17.868459296875%2c17.4754972265625Q17.858859296875%2c17.5237972265625%2c17.840009296875%2c17.5692872265625Q17.821169296875%2c17.6147872265625%2c17.793809296875%2c17.6557372265625Q17.766449296875%2c17.6966772265625%2c17.731629296875%2c17.7315072265625Q17.696799296875%2c17.7663272265625%2c17.655859296875%2c17.7936872265625Q17.614909296875%2c17.8210472265625%2c17.569409296875%2c17.8398872265625Q17.523919296875%2c17.8587372265625%2c17.475619296875%2c17.8683472265625Q17.427319296874998%2c17.8779472265625%2c17.378069296875%2c17.8779472265625Q17.278619296875%2c17.8779472265625%2c17.186729296875%2c17.8398872265625Q17.094849296875%2c17.8018272265625%2c17.024519296875%2c17.7315072265625L13.489035296875%2c14.1960202265625L13.488976296875%2c14.1959602265625Q13.418649296875%2c14.1256342265625%2c13.380589296875%2c14.0337492265625Q13.342529296875%2c13.9418634265625%2c13.342529296875%2c13.8424072265625Q13.342529296875%2c13.7931615265625%2c13.352136296875%2c13.7448621265625Q13.361744296874999%2c13.6965622265625%2c13.380589296875%2c13.6510652265625Q13.399435296875%2c13.6055682265625%2c13.426794296875%2c13.5646222265625Q13.454154296875%2c13.5236762265625%2c13.488976296875%2c13.4888542265625Q13.523798296875%2c13.4540322265625%2c13.564744296875%2c13.4266722265625Q13.605690296875%2c13.3993132265625%2c13.651187296875%2c13.3804672265625Q13.696684296875%2c13.361622226562499%2c13.744984196875%2c13.3520142265625Q13.793283596875%2c13.3424072265625%2c13.842529296875%2c13.3424072265625Q13.941985496875%2c13.3424072265625%2c14.033871296875%2c13.3804672265625Q14.125756296875%2c13.4185272265625%2c14.196082296875%2c13.4888542265625L14.196142296875%2c13.4889132265625Z' fill-rule='evenodd' fill='white' fill-opacity='1'/%3e%3c/g%3e%3c/g%3e%3c/svg%3e)


#【推荐工具: https://material-guide.site/】
这是一个基于 Qwen Image Edit 模型的多角度图像生成工作流,主要用于从单张输入图像生成不同视角的图像。
工作流程概览
该工作流分为以下几个主要步骤:
1. 模型和 VAE 加载 (STEP 1)
- CLIPLoader (节点 38): 加载
qwen_2.5_vl_7b_fp8_scaled.safetensors文本编码器 - VAELoader (节点 39): 加载
qwen_image_vae.safetensorsVAE 模型 - 模型选择器 (节点 244): 在两个模型之间切换:
- 节点 37:
UNETLoader加载标准 FP8 模型 (当前禁用,mode=4) - 节点 241:
NunchakuQwenImageDiTLoader加载量化的 INT4 模型svdq-int4_r32-qwen-image-edit-2509-lightningv2.0-4steps.safetensors(当前启用)
- 节点 37:
2. 模型处理链
模型经过以下处理:
- LoraLoaderModelOnly (节点 89): 应用 Lightning LoRA
Qwen-Image-Lightning-8steps-V1.0.safetensors加速采样 - ModelSamplingAuraFlow (节点 66): 配置采样参数
- CFGNorm (节点 75): 应用 CFG 归一化,强度为 1
3. 输入图像处理 (STEP 2)
- INPUT IMG 1 (节点 78): 加载主输入图像
ltxv-base_00001.png - ImageScale (节点 246): 缩放到 1024x1024
- ImageScaleToTotalPixels (节点 93): 调整总像素数为 1M
- VAEEncode (节点 88): 将图像编码为潜在空间
可选的 INPUT IMG 2 (节点 144-145,当前禁用) 用于添加额外细节如眼镜或帽子。
4. 文本提示编码 (STEP 3)
使用 TextEncodeQwenImageEditPlus 节点生成三个不同视角的条件:
- Prompt 1 (节点 137): "Shows the back-side of the man" - 背面视角
- Prompt 2 (节点 111): "Shows the side view of the man, facing to the left." - 左侧面
- Prompt 3 (节点 128): "Shows the side view of the man, facing to the right." - 右侧面
- 负面提示 (节点 110): "low quality, low resolution, artifacts, bad quality" - 用于所有采样器
5. 采样生成 (SAMPLERS)
三个 KSampler 节点并行运行,生成三个不同视角:
- KSampler 2 (节点 3): 使用 pos 1 和 neg 1,8 步,seed=453336034331422
- KSampler 3 (节点 125): 使用 pos 2 和 neg 1,8 步,seed=921526798321862
- KSampler 1 (节点 132): 使用 pos 3 和 neg 1,8 步,seed=117876004670144
所有采样器使用 euler 采样器和 simple 调度器,去噪强度为 1。
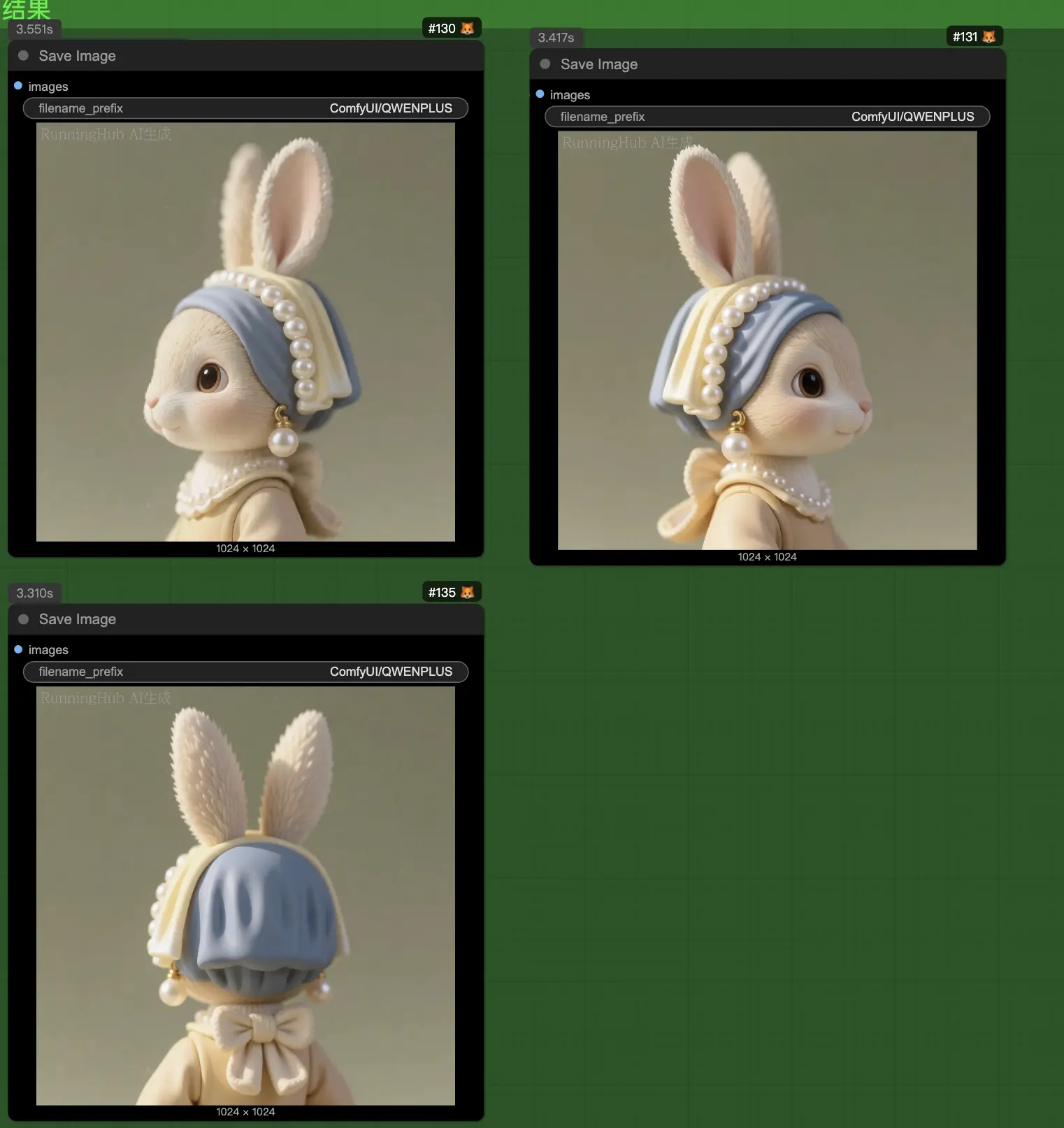
6. 解码和保存 (RESULTS)
- VAEDecode 节点 (8, 126, 136): 将潜在空间解码回图像
- SaveImage 节点 (130, 131, 135, 139): 保存生成的图像到
ComfyUI/QWENPLUS目录
核心机制
工作流使用 SetNode/GetNode 系统实现数据共享,避免重复连接:
- VAE、CLIP、MODEL、输入图像、潜在空间、条件和结果都通过这种方式在节点间传递
- 这使得工作流更整洁,易于维护
Notes
这个工作流专门设计用于多视角图像生成,特别适合角色设计和 3D 建模的参考图生成。 使用量化的 INT4 模型和 Lightning LoRA 可以显著加速生成过程,同时保持较高质量。 节点 148 的注释提到可以启用第二个输入图像来添加配饰等细节。
'%3e%3cpath d='M22.941142499999998%2c18.4907265625C20.7973025%2c21.2337465625%2c18.653602499999998%2c23.9764965625%2c16.5096155%2c26.719196562500002C15.7464715%2c27.6958965625%2c16.4596735%2c29.1035265625%2c17.7179125%2c29.1035265625L30.5804125%2c29.1035265625C31.8385125%2c29.1035265625%2c32.5519125%2c27.6958965625%2c31.7883125%2c26.719196562500002C29.6448125%2c23.9764965625%2c27.500812500000002%2c21.2337965625%2c25.3570725%2c18.4907265625C24.7489725%2c17.7127265625%2c23.5494225%2c17.7127265625%2c22.941142499999998%2c18.4907265625ZM24.0441925%2c19.3528665625L24.0440425%2c19.3530465625L19.6246325%2c25.0074065625L17.6126225%2c27.5813865625Q17.5882425%2c27.6125865625%2c17.6045625%2c27.6447765625Q17.6343025%2c27.7034865625%2c17.7179125%2c27.7034865625L30.5804125%2c27.7034865625Q30.663912500000002%2c27.7034865625%2c30.6937125%2c27.6448265625Q30.7099125%2c27.6128265625%2c30.685412499999998%2c27.5814965625L24.254022499999998%2c19.3528565625Q24.2183525%2c19.3072265625%2c24.149182500000002%2c19.3072265625Q24.0800125%2c19.3072265625%2c24.0441925%2c19.3528665625Z' fill-rule='evenodd' fill='%23BEC4CA' fill-opacity='1'/%3e%3c/g%3e%3c/g%3e%3c/svg%3e) 43
43'%3e%3cg%3e%3cpath d='M16.45%2c9L16.45%2c15.75Q16.45%2c15.81894%2c16.436500000000002%2c15.88656Q16.423099999999998%2c15.954180000000001%2c16.3967%2c16.017879999999998Q16.3703%2c16.08157%2c16.332%2c16.1389Q16.2937%2c16.19622%2c16.244999999999997%2c16.244979999999998Q16.196199999999997%2c16.29373%2c16.1389%2c16.33203Q16.0816%2c16.37033%2c16.017899999999997%2c16.396720000000002Q15.9542%2c16.423099999999998%2c15.8866%2c16.43655Q15.8189%2c16.45%2c15.75%2c16.45L2.25%2c16.45Q2.181056%2c16.45%2c2.1134370000000002%2c16.43655Q2.045818%2c16.423099999999998%2c1.982122%2c16.39671Q1.918426%2c16.37033%2c1.8611010000000001%2c16.33203Q1.803776%2c16.29373%2c1.755025%2c16.244970000000002Q1.706275%2c16.19622%2c1.667971%2c16.1389Q1.6296680000000001%2c16.08157%2c1.603284%2c16.017879999999998Q1.5769009999999999%2c15.954180000000001%2c1.56345%2c15.88656Q1.55%2c15.81894%2c1.55%2c15.75L1.55%2c9.00311222Q1.55%2c8.9341683%2c1.56345%2c8.866549Q1.5769009999999999%2c8.79893%2c1.603284%2c8.735234Q1.6296680000000001%2c8.671538%2c1.667971%2c8.614213Q1.706275%2c8.556888%2c1.755025%2c8.508138Q1.803776%2c8.459387%2c1.8611010000000001%2c8.421084Q1.918426%2c8.38278%2c1.982122%2c8.356397Q2.045818%2c8.330013%2c2.1134370000000002%2c8.316563Q2.181056%2c8.303112%2c2.25%2c8.303112Q2.318944%2c8.303112%2c2.3865629999999998%2c8.316563Q2.454182%2c8.330013%2c2.517878%2c8.356397Q2.581574%2c8.38278%2c2.638899%2c8.421084Q2.696224%2c8.459387%2c2.744975%2c8.508137Q2.7937250000000002%2c8.556888%2c2.832029%2c8.614213Q2.870332%2c8.671538%2c2.896716%2c8.735234Q2.923099%2c8.79893%2c2.93655%2c8.866549Q2.95%2c8.9341682%2c2.95%2c9.0031122L2.95%2c15.05L15.05%2c15.05L15.05%2c9Q15.05%2c8.931056%2c15.0634%2c8.863437Q15.0769%2c8.795818%2c15.1033%2c8.732122Q15.1297%2c8.668426%2c15.168%2c8.611101Q15.2063%2c8.553776%2c15.255%2c8.505025Q15.3038%2c8.456275%2c15.3611%2c8.417971Q15.4184%2c8.379668%2c15.4821%2c8.353284Q15.5458%2c8.326901%2c15.6134%2c8.31345Q15.6811%2c8.3%2c15.75%2c8.3Q15.8189%2c8.3%2c15.8866%2c8.31345Q15.9542%2c8.326901%2c16.017899999999997%2c8.353284Q16.0816%2c8.379668%2c16.1389%2c8.417971Q16.196199999999997%2c8.456275%2c16.244999999999997%2c8.505025Q16.2937%2c8.553776%2c16.332%2c8.611101Q16.3703%2c8.668426%2c16.3967%2c8.732122Q16.423099999999998%2c8.795818%2c16.436500000000002%2c8.863437Q16.45%2c8.931056%2c16.45%2c9Z' fill-rule='evenodd' fill='%23BEC4CA' fill-opacity='1'/%3e%3c/g%3e%3cg%3e%3cpath d='M6.120042%2c8.13058028125L9%2c11.01053828125L11.87999%2c8.13054428125L11.88003%2c8.13051328125Q11.978480000000001%2c8.03205728125%2c12.10712%2c7.97877228125Q12.235759999999999%2c7.92548828125%2c12.375%2c7.92548828125Q12.44394%2c7.92548828125%2c12.51156%2c7.93893828125Q12.579180000000001%2c7.95238928125%2c12.64288%2c7.97877228125Q12.70657%2c8.00515628125%2c12.7639%2c8.04345928125Q12.82122%2c8.08176328125%2c12.86997%2c8.13051328125Q12.91872%2c8.17926428125%2c12.95703%2c8.23658928125Q12.99533%2c8.29391428125%2c13.021709999999999%2c8.35761028125Q13.0481%2c8.42130628125%2c13.06155%2c8.48892528125Q13.075%2c8.55654428125%2c13.075%2c8.62548828125Q13.075%2c8.76472728125%2c13.02172%2c8.89336628125Q12.96843%2c9.02200628125%2c12.86997%2c9.12046328125L12.86994%2c9.12049328125L9.49497%2c12.49545828125Q9.39652%2c12.59391828125%2c9.26788%2c12.64720828125Q9.139240000000001%2c12.70048828125%2c9%2c12.70048828125Q8.860759999999999%2c12.70048828125%2c8.73212%2c12.64720828125Q8.60348%2c12.59391828125%2c8.50503%2c12.49545828125L5.130025%2c9.12046328125Q5.031569%2c9.02200628125%2c4.978284%2c8.89336628125Q4.925%2c8.76472728125%2c4.925%2c8.62548828125Q4.925%2c8.55654428125%2c4.93845%2c8.48892528125Q4.951901%2c8.42130628125%2c4.978284%2c8.35761028125Q5.004668%2c8.29391428125%2c5.042971%2c8.23658928125Q5.081275%2c8.17926428125%2c5.130025%2c8.13051328125Q5.178776%2c8.08176328125%2c5.236101%2c8.04345928125Q5.293426%2c8.00515628125%2c5.357122%2c7.97877228125Q5.420818%2c7.95238928125%2c5.488437%2c7.93893828125Q5.556056%2c7.92548828125%2c5.625%2c7.92548828125Q5.764239%2c7.92548828125%2c5.892878%2c7.97877228125Q6.021518%2c8.03205728125%2c6.119975%2c8.13051328125L6.120042%2c8.13058028125Z' fill-rule='evenodd' fill='%23BEC4CA' fill-opacity='1'/%3e%3c/g%3e%3cg%3e%3cpath d='M8.29560546875%2c2.25Q8.29560546875%2c2.181056%2c8.30905546875%2c2.1134370000000002Q8.32250646875%2c2.045818%2c8.34888946875%2c1.982122Q8.37527346875%2c1.918426%2c8.41357646875%2c1.8611010000000001Q8.45188046875%2c1.803776%2c8.50063046875%2c1.755025Q8.54938146875%2c1.706275%2c8.60670646875%2c1.667971Q8.66403146875%2c1.6296680000000001%2c8.72772746875%2c1.603284Q8.79142346875%2c1.5769009999999999%2c8.85904246875%2c1.56345Q8.92666146875%2c1.55%2c8.99560546875%2c1.55Q9.06454946875%2c1.55%2c9.13216846875%2c1.56345Q9.19978746875%2c1.5769009999999999%2c9.26348346875%2c1.603284Q9.32717946875%2c1.6296680000000001%2c9.38450446875%2c1.667971Q9.44182946875%2c1.706275%2c9.49058046875%2c1.755025Q9.53933046875%2c1.803776%2c9.57763446875%2c1.8611010000000001Q9.61593746875%2c1.918426%2c9.64232146875%2c1.982122Q9.66870446875%2c2.045818%2c9.68215546875%2c2.1134370000000002Q9.69560546875%2c2.181056%2c9.69560546875%2c2.25L9.69560546875%2c12Q9.69560546875%2c12.06894%2c9.68215546875%2c12.13656Q9.66870446875%2c12.20418%2c9.64232146875%2c12.2679Q9.61593746875%2c12.3316%2c9.57763446875%2c12.3889Q9.53933046875%2c12.4462%2c9.49058046875%2c12.495Q9.44182946875%2c12.5437%2c9.38450446875%2c12.582Q9.32717946875%2c12.6203%2c9.26348346875%2c12.6467Q9.19978746875%2c12.6731%2c9.13216846875%2c12.6865Q9.06454946875%2c12.7%2c8.99560546875%2c12.7Q8.92666146875%2c12.7%2c8.85904246875%2c12.6866Q8.79142346875%2c12.6731%2c8.72772746875%2c12.6467Q8.66403146875%2c12.6203%2c8.60670646875%2c12.582Q8.54938146875%2c12.5437%2c8.50063046875%2c12.495Q8.45188046875%2c12.4462%2c8.41357646875%2c12.3889Q8.37527346875%2c12.3316%2c8.34888946875%2c12.2679Q8.32250646875%2c12.20418%2c8.30905546875%2c12.13656Q8.29560546875%2c12.06894%2c8.29560546875%2c12L8.29560546875%2c2.25Z' fill-rule='evenodd' fill='%23BEC4CA' fill-opacity='1'/%3e%3c/g%3e%3c/g%3e%3c/svg%3e) 下载
下载 0
0 5
5'%3e%3cg%3e%3cpath d='M2.00048828125%2c13.15673828125C2.00048828125%2c13.43287828125%2c2.22434628125%2c13.65673828125%2c2.50048828125%2c13.65673828125L3.00048828125%2c13.65673828125L3.00048828125%2c6.15673828125C3.00048828125%2c5.88059628125%2c2.77663028125%2c5.65673828125%2c2.50048828125%2c5.65673828125C2.22434628125%2c5.65673828125%2c2.00048828125%2c5.88059628125%2c2.00048828125%2c6.15673828125L2.00048828125%2c13.15673828125Z' fill='%23D8D8D8' fill-opacity='1'/%3e%3c/g%3e%3cg transform='matrix(0%2c1%2c-1%2c0%2c22.656814575195312%2c2.6558380126953125)'%3e%3cpath d='M10.00048828125%2c13.156326293945312L10.00048828125%2c20.656326293945312L10.50048828125%2c20.656326293945312C10.77663028125%2c20.656326293945312%2c11.00048828125%2c20.43246629394531%2c11.00048828125%2c20.156326293945312L11.00048828125%2c13.156326293945312C11.00048828125%2c12.880184293945312%2c10.77663028125%2c12.656326293945312%2c10.50048828125%2c12.656326293945312C10.22434628125%2c12.656326293945312%2c10.00048828125%2c12.880184293945312%2c10.00048828125%2c13.156326293945312Z' fill='%23D8D8D8' fill-opacity='1'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
#【推荐工具: https://material-guide.site/】
这是一个基于 Qwen Image Edit 模型的多角度图像生成工作流,主要用于从单张输入图像生成不同视角的图像。
工作流程概览
该工作流分为以下几个主要步骤:
1. 模型和 VAE 加载 (STEP 1)
- CLIPLoader (节点 38): 加载
qwen_2.5_vl_7b_fp8_scaled.safetensors文本编码器 - VAELoader (节点 39): 加载
qwen_image_vae.safetensorsVAE 模型 - 模型选择器 (节点 244): 在两个模型之间切换:
- 节点 37:
UNETLoader加载标准 FP8 模型 (当前禁用,mode=4) - 节点 241:
NunchakuQwenImageDiTLoader加载量化的 INT4 模型svdq-int4_r32-qwen-image-edit-2509-lightningv2.0-4steps.safetensors(当前启用)
- 节点 37:
2. 模型处理链
模型经过以下处理:
- LoraLoaderModelOnly (节点 89): 应用 Lightning LoRA
Qwen-Image-Lightning-8steps-V1.0.safetensors加速采样 - ModelSamplingAuraFlow (节点 66): 配置采样参数
- CFGNorm (节点 75): 应用 CFG 归一化,强度为 1
3. 输入图像处理 (STEP 2)
- INPUT IMG 1 (节点 78): 加载主输入图像
ltxv-base_00001.png - ImageScale (节点 246): 缩放到 1024x1024
- ImageScaleToTotalPixels (节点 93): 调整总像素数为 1M
- VAEEncode (节点 88): 将图像编码为潜在空间
可选的 INPUT IMG 2 (节点 144-145,当前禁用) 用于添加额外细节如眼镜或帽子。
4. 文本提示编码 (STEP 3)
使用 TextEncodeQwenImageEditPlus 节点生成三个不同视角的条件:
- Prompt 1 (节点 137): "Shows the back-side of the man" - 背面视角
- Prompt 2 (节点 111): "Shows the side view of the man, facing to the left." - 左侧面
- Prompt 3 (节点 128): "Shows the side view of the man, facing to the right." - 右侧面
- 负面提示 (节点 110): "low quality, low resolution, artifacts, bad quality" - 用于所有采样器
5. 采样生成 (SAMPLERS)
三个 KSampler 节点并行运行,生成三个不同视角:
- KSampler 2 (节点 3): 使用 pos 1 和 neg 1,8 步,seed=453336034331422
- KSampler 3 (节点 125): 使用 pos 2 和 neg 1,8 步,seed=921526798321862
- KSampler 1 (节点 132): 使用 pos 3 和 neg 1,8 步,seed=117876004670144
所有采样器使用 euler 采样器和 simple 调度器,去噪强度为 1。
6. 解码和保存 (RESULTS)
- VAEDecode 节点 (8, 126, 136): 将潜在空间解码回图像
- SaveImage 节点 (130, 131, 135, 139): 保存生成的图像到
ComfyUI/QWENPLUS目录
核心机制
工作流使用 SetNode/GetNode 系统实现数据共享,避免重复连接:
- VAE、CLIP、MODEL、输入图像、潜在空间、条件和结果都通过这种方式在节点间传递
- 这使得工作流更整洁,易于维护
Notes
这个工作流专门设计用于多视角图像生成,特别适合角色设计和 3D 建模的参考图生成。 使用量化的 INT4 模型和 Lightning LoRA 可以显著加速生成过程,同时保持较高质量。 节点 148 的注释提到可以启用第二个输入图像来添加配饰等细节。