qwen-image-Q3_K_M.gguf 8
8 0
0 7
7
8 0 7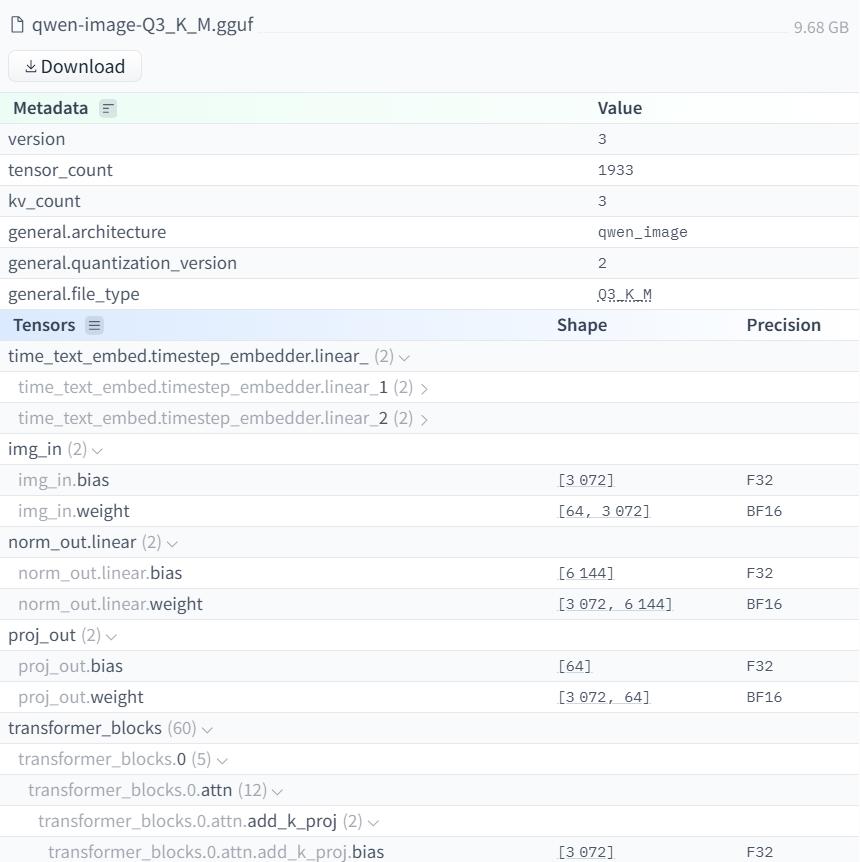
This is a direct GGUF conversion of Qwen/Qwen-Image.
The model files can be used in ComfyUI with the ComfyUI-GGUF custom node. Place the required model(s) in the following folders:
| Type | Name | Location | Download |
|---|---|---|---|
| Main Model | Qwen-Image | ComfyUI/models/diffusion_models | GGUF (this repo) |
| Text Encoder | Qwen2.5-VL-7B | ComfyUI/models/text_encoders | Safetensors / GGUF |
| VAE | Qwen-Image VAE | ComfyUI/models/vae | Safetensors |
Example outputs - sample size of 1, not strictly representative

The Q5_K_M, Q4_K_M and most importantly the low bitrate quants (Q3_K_M, Q3_K_S, Q2_K) use a new dynamic logic where the first/last layer is kept in high precision.
For a comparison, see this imgsli page. With this method, even Q2_K remains somewhat usable.
As this is a quantized model not a finetune, all the same restrictions/original license terms still apply.
模型信息
'%3e%3cg%3e%3cpath d='M6.9375%2c1.875L14.8125%2c1.875C15.5374%2c1.875000858307%2c16.125%2c2.462627%2c16.125%2c3.1875L16.125%2c11.0625C16.125%2c11.78737%2c15.5374%2c12.375%2c14.8125%2c12.375L6.9375%2c12.375C6.21263%2c12.375%2c5.625%2c11.78737%2c5.625%2c11.0625L5.625%2c3.1875C5.625%2c2.462626%2c6.21263%2c1.875000343323%2c6.9375%2c1.875ZM6.9375%2c3C6.83395%2c3%2c6.75%2c3.0839499999999997%2c6.75%2c3.1875L6.75%2c11.0625C6.75%2c11.16605%2c6.83395%2c11.25%2c6.9375%2c11.25L14.8125%2c11.25C14.9161%2c11.25%2c15%2c11.16605%2c15%2c11.0625L15%2c3.1875C15%2c3.0839499999999997%2c14.9161%2c3%2c14.8125%2c3L6.9375%2c3ZM11.25%2c13.5C11.25%2c13.1893%2c11.50184%2c12.9375%2c11.8125%2c12.9375C12.1232%2c12.9375%2c12.375%2c13.1893%2c12.375%2c13.5L12.375%2c14.8125C12.375%2c15.5374%2c11.78737%2c16.125%2c11.0625%2c16.125L3.1875%2c16.125C2.462626%2c16.125%2c1.875000171661%2c15.5374%2c1.875%2c14.8125L1.875%2c6.9375C1.875%2c6.21263%2c2.462626%2c5.625%2c3.1875%2c5.625L4.5%2c5.625C4.81066%2c5.625%2c5.0625%2c5.87684%2c5.0625%2c6.1875C5.0625%2c6.49816%2c4.81066%2c6.75%2c4.5%2c6.75L3.1875%2c6.75C3.0839499999999997%2c6.75%2c3%2c6.83395%2c3%2c6.9375L3%2c14.8125C3%2c14.9161%2c3.0839499999999997%2c15%2c3.1875%2c15L11.0625%2c15C11.16605%2c15%2c11.25%2c14.9161%2c11.25%2c14.8125L11.25%2c13.5Z' fill='%239DA2A8' fill-opacity='1' style='mix-blend-mode:passthrough'/%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
This is a direct GGUF conversion of Qwen/Qwen-Image.
The model files can be used in ComfyUI with the ComfyUI-GGUF custom node. Place the required model(s) in the following folders:
| Type | Name | Location | Download |
|---|---|---|---|
| Main Model | Qwen-Image | ComfyUI/models/diffusion_models | GGUF (this repo) |
| Text Encoder | Qwen2.5-VL-7B | ComfyUI/models/text_encoders | Safetensors / GGUF |
| VAE | Qwen-Image VAE | ComfyUI/models/vae | Safetensors |
Example outputs - sample size of 1, not strictly representative
The Q5_K_M, Q4_K_M and most importantly the low bitrate quants (Q3_K_M, Q3_K_S, Q2_K) use a new dynamic logic where the first/last layer is kept in high precision.
For a comparison, see this imgsli page. With this method, even Q2_K remains somewhat usable.
As this is a quantized model not a finetune, all the same restrictions/original license terms still apply.